Hi Everyone!!
Today we had issues in 2 node Exadata RAC cluster with high concurrency wait "library cache: mutex X". Posting this as it would help some one out there later point in time.
OEM was showing high concurrency waits on the graph which was not normal.
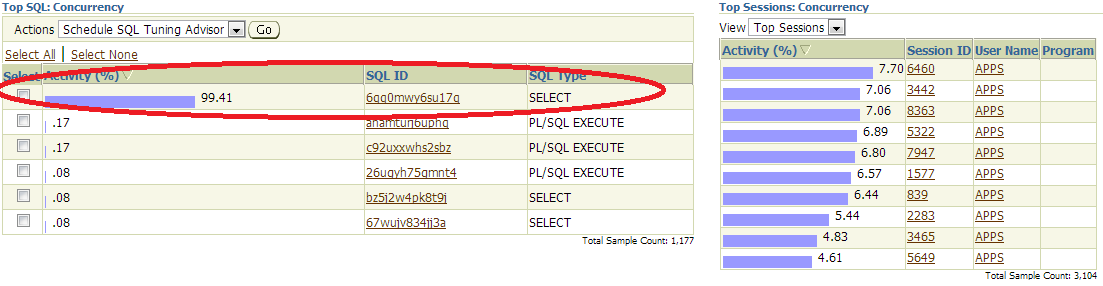
 After checking the concurrent top SQL, one of the select statement was causing 99% of the issue.
After checking the concurrent top SQL, one of the select statement was causing 99% of the issue.
 SQL running behind was from concurrent manager. !!
SQL running behind was from concurrent manager. !!
That gave the idea to check out all the concurrent manager related logs.
Standard manager log was having below error message
The SQL statement being executed at the time of the error was: update fnd_concurrent_requests set phase_code = :phase ,status_code = :status, completion_text = :text where request_id = :reqid and was executed from the file &ERRFILE.
User PAULPET or Responsibility AR Corp Pmt Processing User has expired. Cannot process request 45692490.
APP-FND-01564: ORACLE error 1002 in UPDATE_STATUS
Cause: UPDATE_STATUS failed due to ORA-01002: fetch out of sequence.
Then it became for us to understand the cause. User has scheduled the jobs where user ID was terminated. Concurrent manager processes started spinning around. we have terminated standard manager and removed the scheduled jobs from the system. Systems wait event graph came back to normal.
Metalink suggested fix patch for this issue. :)
Today we had issues in 2 node Exadata RAC cluster with high concurrency wait "library cache: mutex X". Posting this as it would help some one out there later point in time.
OEM was showing high concurrency waits on the graph which was not normal.

That gave the idea to check out all the concurrent manager related logs.
SELECT R.Conc_Login_Id, R.Request_Id, R.Phase_Code, R.Status_Code,
P.Application_ID, P.Concurrent_Program_ID, P.Concurrent_Program_Name,
R.Enable_Trace, R.Restart, DECODE(R.Increment_Dates, 'Y', 'Y', 'N'),
R.NLS_Compliant, R.OUTPUT_FILE_TYPE, E.Executable_Name, E.Execution_File_Name,
A2.Basepath, DECODE(R.Stale, 'Y', 'C', P.Execution_Method_Code), P.Print_Flag,
P.Execution_Options, DECODE(P.Srs_Flag, 'Y', 'Y', 'Q', 'Y', 'N'),
P.Argument_Method_Code, R.Print_Style, R.Argument_Input_Method_Code,
R.Queue_Method_Code, R.Responsibility_ID, R.Responsibility_Application_ID,
R.Requested_By, R.Number_Of_Copies, R.Save_Output_Flag, R.Printer,
R.Print_Group, R.Priority, U.User_Name, O.Oracle_Username,
O.Encrypted_Oracle_Password, R.Cd_Id, A.Basepath, A.Application_Short_Name,
TO_CHAR(R.Requested_Start_Date,'YYYY/MM/DD HH24:MI:SS'), R.Nls_Language,
R.Nls_Territory, DECODE(R.Parent_Request_ID, NULL, 0, R.Parent_Request_ID),
R.Priority_Request_ID, R.Single_Thread_Flag, R.Has_Sub_Request, R.Is_Sub_Request,
R.Req_Information, R.Description, R.Resubmit_Time,
TO_CHAR(R.Resubmit_Interval), R.Resubmit_Interval_Type_Code,
R.Resubmit_Interval_Unit_Code, TO_CHAR(R.Resubmit_End_Date,'YYYY/MM/DD
HH24:MI:SS'), Decode(E.Execution_File_Name, NULL, 'N', Decode(E.Subroutine_Name,
NULL, Decode(E.Execution_Method_Code, 'I', 'Y', 'J', 'Y', 'N'), 'Y')),
R.Argument1, R.Argument2, R.Argument3, R.Argument4,
R.Argument5, R.Argument6, R.Argument7, R.Argument8,
R.Argument9, R.Argument10, R.Argument11, R.Argument12, R.Argument13,
R.Argument14, R.Argument15, R.Argument16, R.Argument17, R.Argument18,
R.Argument19,
...
... Truncated the sql for readability purpose
...
(20214,39804),(20214,39838),(20214,40937))
AND R.REQUESTED_BY NOT IN (20829,21465,192077))) FOR UPDATE OF R.status_code
NoWait
Standard manager log was having below error message
The SQL statement being executed at the time of the error was: update fnd_concurrent_requests set phase_code = :phase ,status_code = :status, completion_text = :text where request_id = :reqid and was executed from the file &ERRFILE.
User PAULPET or Responsibility AR Corp Pmt Processing User has expired. Cannot process request 45692490.
APP-FND-01564: ORACLE error 1002 in UPDATE_STATUS
Cause: UPDATE_STATUS failed due to ORA-01002: fetch out of sequence.
Then it became for us to understand the cause. User has scheduled the jobs where user ID was terminated. Concurrent manager processes started spinning around. we have terminated standard manager and removed the scheduled jobs from the system. Systems wait event graph came back to normal.
Metalink suggested fix patch for this issue. :)
We have fix patch 9109247 for
this issue “Scheduled Requests Running for END_DATED Users 100% CPU and Giving
ORA-01002 [ID 1080047.1]”
Hope this will help someone.!!

3 comments:
Thank you so much for posting this. You saved me many frustrating hours trying to find out why we were experiencing this problem after our 11g upgrade.
Thank you so much for posting this. You saved me many frustrating hours trying to find out why we were experiencing this problem after our 11g upgrade.
Thank you a lot for posting this! Exactly our issue, applying the patch in test at the moment
Post a Comment